Anatomy of a Sub-400ms STT→LLM→TTS Pipeline
By Sev Geraskin

The One Second Rule
At the one-second mark, users begin to disengage. Human conversation simply breaks. Human speech has a rhythm. When you ask someone a question, and they pause for more than 800ms before responding, your brain starts to file it as awkward. At 1.2 seconds, you start wondering if they heard you. At two seconds, you reach for the “end call” button.
Voice AI that can’t match that rhythm is broken, regardless of how many parameters its model has or how many benchmarks it passed.
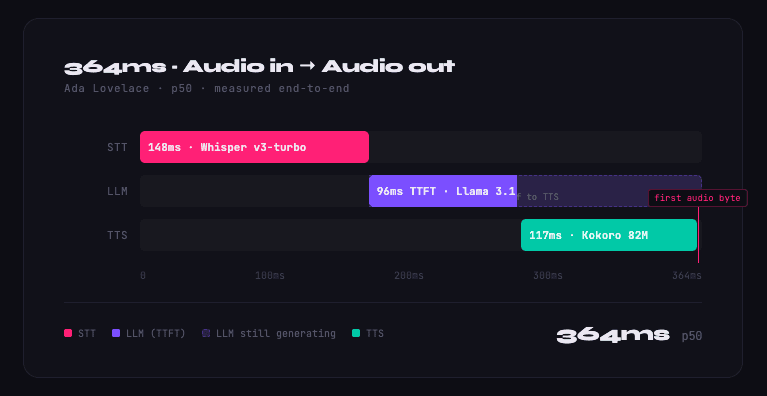
At PolarGrid, our current pre-production benchmarks on Ada Lovelace architecture show 364ms p50 end-to-end latency, measured from audio input to audio output across real network round-trip time. With our Blackwell deployment underway, we are projecting a p50 of sub-300ms. This post explains the architecture behind both numbers and the path between them.
The Latency Budget
We started with a 300ms production ceiling and worked backwards, allocating budget to each stage before writing a line of code. The breakdown we designed for Blackwell:
- STT: 80ms. Transcription fast enough that the LLM can begin processing immediately.
- LLM: 100ms. Time-to-first-token: TTS does not need to wait for a complete response before starting.
- TTS: 70ms. Time-to-first-byte of audio: streaming synthesis runs in parallel with continued LLM generation.
- Network: 30ms. Round-trip: the speed-of-light tax.
- Overhead: 20ms. VAD onset, serialization between stages, and WebRTC framing overhead.
On Ada Lovelace today, we land at 364ms p50: STT at 148ms, LLM at 96ms, TTS at 117ms. Blackwell’s higher memory bandwidth, improved tensor core throughput, and enhanced FP8 quantization support are what close the gap to 300ms.
The Three Stages
Stage 1: Speech-to-Text (Ada: 148ms | Blackwell target: 80ms)
We run Whisper large-v3-turbo for transcription. The turbo variant hits a specific inflection point: it handles real-world speech, accents, background noise, and incomplete sentences, without the latency penalty of the full large model.
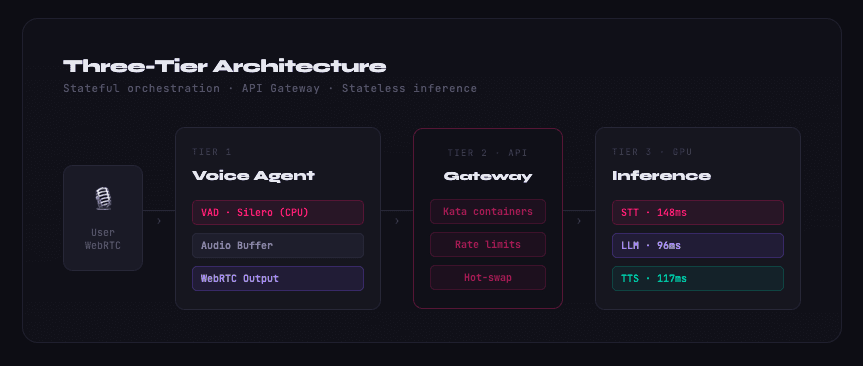
Our approach separates voice detection from transcription entirely. We run Silero VAD continuously in the background on the CPU. It’s cheap, highly accurate, and leaves all GPU headroom strictly for inference. As the user speaks, we build an audio buffer in memory. The exact millisecond Silero detects the end of speech, that complete, clean audio chunk is sent to the STT model via the Gateway.
We don’t waste time spinning up Whisper until we know the user has finished their thought. On queries under ten words, this clean handoff keeps our STT latency tight, and because the audio boundary is clearly defined, the LLM starts with perfect context rather than correcting speculative transcription errors mid-flight.
Stage 2: LLM Inference (Ada: 96ms | Blackwell target: already met)
The LLM stage is where most voice pipelines give up. They use the same serving infrastructure they’d use for a chatbot. Yet chatbots optimize for throughput over latency. With servers located on the other side of the continent, they wonder why they’re sitting at 800ms time-to-first-token.
The other problem is batching. Standard LLM serving (vLLM’s continuous batching, TensorRT-LLM’s static batching) groups requests together to maximize GPU utilization. This is the right design for email summarization. For voice, batching is the enemy. Every millisecond your request sits in a queue waiting for other requests is a millisecond of the user’s patience burned.
We run Llama 3.1 8B via Triton with a dedicated serving configuration optimized for single-request latency over aggregate throughput. The memory footprint is ~18GB of VRAM, leaving headroom to serve concurrent voice sessions without model contention.
Stage 3: Text-to-Speech (Ada: 117ms | Blackwell target: 70ms)
TTS is the stage most voice platforms treat as an afterthought. They call ElevenLabs or OpenAI TTS. The network round-trip alone adds 200–400ms. The model isn’t colocated with the LLM. The audio format requires additional transcoding.
We run Kokoro-82M, a compact but surprisingly capable TTS model that runs on the same GPU node as the STT and LLM. No external API calls. No cross-datacenter hops between pipeline stages.
Kokoro returns raw PCM at 24kHz. We wrap it in a WAV container client-side. No server-side transcoding. The result is first audio byte in 117ms on Ada Lovelace, targeting 70ms on Blackwell.
The key architectural decision: all three models — Whisper, Llama, Kokoro — run on the same physical node. The inter-stage latency is a memory copy, not a network call.
What Blackwell Changes
The RTX PRO 6000 Blackwell cards we’re deploying have two properties that matter for this pipeline:
Higher memory bandwidth (1,792 GB/s vs 960 GB/s on Ada Lovelace) directly reduces token generation time. For a model like Llama 3.1 8B, memory bandwidth is the primary bottleneck during autoregressive decoding. More bandwidth means faster token generation means lower time-to-first-token.
FP8 quantization support cuts model memory footprint roughly in half without meaningful accuracy degradation. Smaller footprint means more of the model fits in L2 cache. More cache hits means fewer DRAM accesses means lower latency on each forward pass.
The combination is what closes the gap from 364ms to sub-300ms. The architecture stays the same. The hardware does the work.
Production Numbers
Our live Toronto node running Ada Lovelace:
- p50 end-to-end: 364ms
- p95 end-to-end: 403ms
- STT: 148ms
- LLM (time-to-first-token): 96ms
- TTS (time-to-first-byte): 117ms
- Network round-trip: ~30ms (within coverage area)
These are measured from audio input to audio output, including real network round-trip time, not synthetic benchmarks in a datacenter loop.
Try PolarGrid today
$500 in free credits. No card required. Sub-400ms voice pipeline live now.
Start Free →